
昨天提到 Timeout 的其中一個原因,就是機器資源不足或是超載的異常,當大量的 Request 發生時,可能會讓機器在 Memory, Disk, CPU 等等環節出現異常,而今天的 Health Check Based Monitoring 主要就是去偵測這些異常,讓 Inference Service 保持 Health 可連通的狀態
Health Check Based Monitoring 的偵測目標: Inference Instance 是否還在正常運作中,其中今天想介紹 Serverless 的方式去時做監控系統達到這目標
Serverless 又稱 FaaS,可以參考下圖:
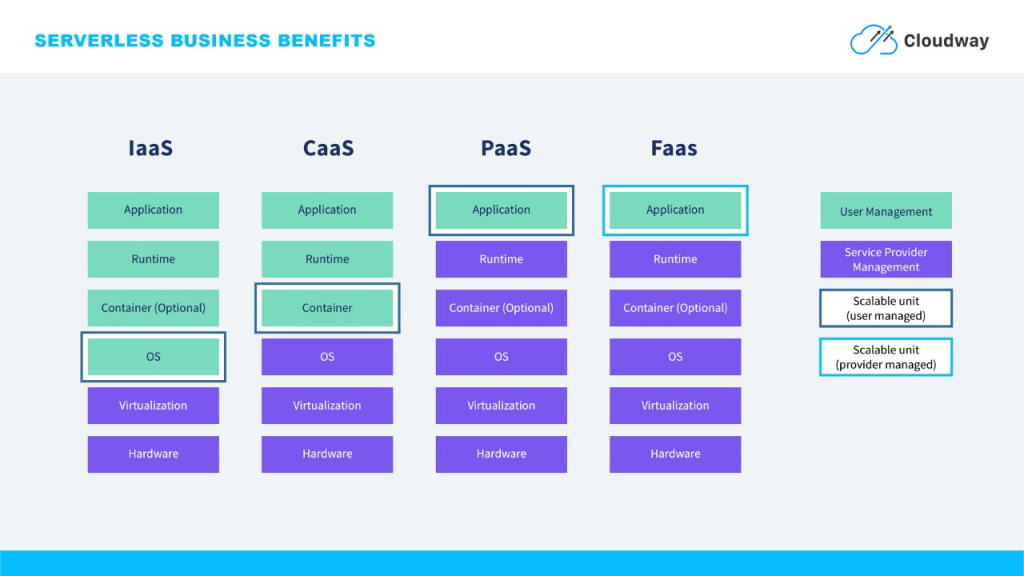
之所以選擇 Serverless 在監控題目中最主要的原因是我希望降低自己需要額外去監測監測系統的成本,透過 Faas 提供的 Auto Scaling 和 Fast Deployment 特性,在搭配 Serverless 監控時需要以下三個元件,這裡一樣以 AWS 提供的功能為例
Serverless 架構為 MLOps 中的模型監控提供了一種靈活、可擴展和成本效益的解決方案,並且有像是 Serverless.com 這樣 Iaas 的解決方案,來達到穩定部署和可依賴的監控

 iThome鐵人賽
iThome鐵人賽